ChemBench: how to build robust frameworks for evaluation of large language models?

Characteristics of a strong benchmark
We build a streamlined pipeline that is end-to-end automated for model testing, which has been lacking from previous chemistry-related LLM benchmarks. We attempt to list several crucial characteristics that would define a useful and practical LLM benchmark:
- End-to-end automation
For model development, the evaluations must be run many times (e.g., on regular intervals of a training run). Approaches that rely on humans scoring the answers of a system can thus not be used. 1, 2, 3
- Careful validation of questions by experts
Manual curation is needed to minimize the number of incorrect or unanswerable questions.4 This is motivated by the observation that many widely used benchmarks are noisy. 5 , 6
- Usable with models that support special treatment of molecules.
Some models, such as Galactica, use special tokenization or encoding procedures for molecules or equations. To support this, the benchmark system must encode the semantic meaning of various parts of the question or answer.
- Usable with black-box systems
Many highly relevant systems do not provide access to model weights or raw logits. This might be the case because the systems are proprietary or involve not only LLMs but also external tools such as search APIs or code executors. Thus, a benchmark should not assume access to the raw model outputs but be able to operate on text completions.
- Probing capabilities beyond answering of MCQs
In the real world, chemistry, as well as higher-level university education, seldom uses multiple-choice questions. Yet, most benchmarking frameworks focus on the MCQ setting because of the ease of evaluation. Realistic evaluations must measure capabilities beyond the answering of MCQ. This does not completely disregard the use case for MCQs, which can be relevant if a subset of answers is available (e.g., when performing chemical synthesis through known reaction mechanisms).
- Cover a diverse set of topics
Chemistry, as the “central science,” bridges multiple disciplines. To even just approximate “chemistry capabilities,” the topics covered by a chemistry benchmark must be very diverse.
Moreover, benchmarking models is not trivial as the quantitive results of a comprehensive benchmark hinge on plenty of details, such as:
- prompting structure (e.g. chain-of-thought vs action-only)
- model output parsing
- model restrictions (safety filters of LLMs)
- score on the generated text or on the numerical probabilities
Workflow
ChemBench has been a great effort from our team to build a large corpus of questions on diverse chemistry tasks (in total >7000 questions). We show the detailed workflow in the Figure below, where we go through three steps:
- Data preparation
- Querying models on all questions and humans on a subset
- Joint leaderboard of models and humans for the joint subset

The leaderboards are available on our web app.
Focus on safety
When one thinks of integrating LLMs with lab work, it is important to assess what these models know about safety specifically. Previous benchmarks largely disregarded this prime aspect of chemistry. Visualizing the diversity by using the PCA-projected embeddings for all of our questions, it is important to acknowledge the presence of a large distinct cluster relating to safety and toxicology. Overall, more than half of the questions in our corpus relate to safety.
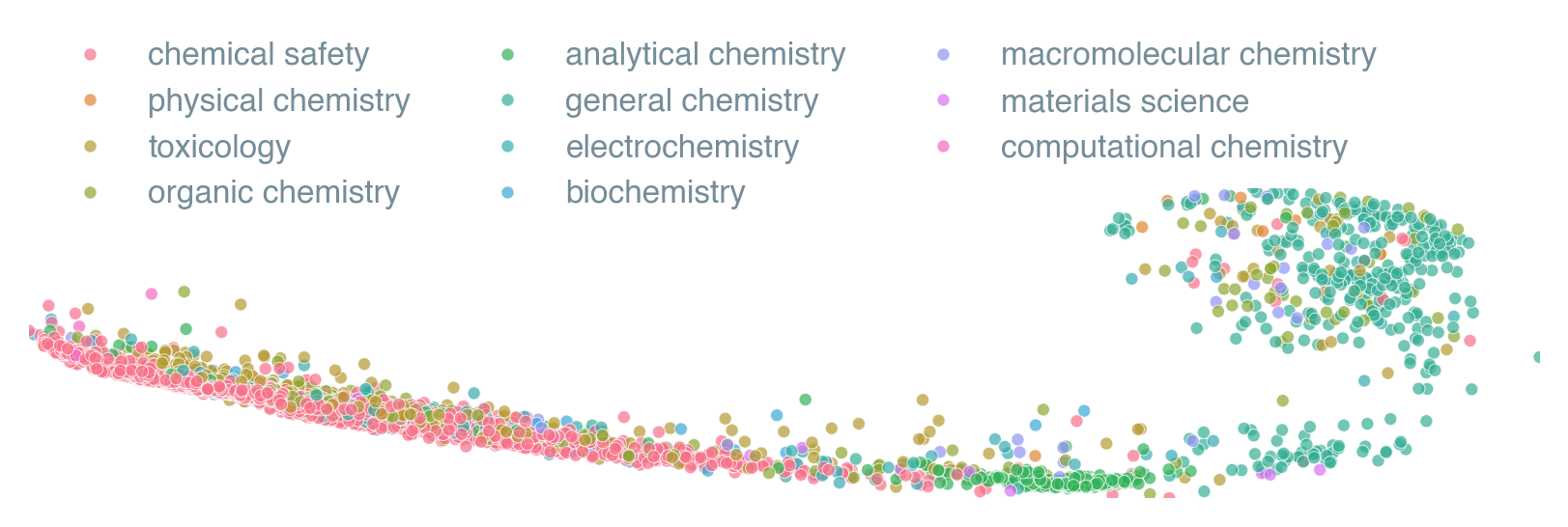
Comprehensive benchmarking
Chemists are increasingly finding great use cases for LLMs, so it is important to look at what these models know about our favorite field. We looked at eight models (both closed-source and open-weight). In the figure below is the list of models and their performance in a radar plot. Claude 3 is the best-performing model in the subset answered by humans, followed by GPT-4 and Claude 2. This is an absolute win for the closed-source models. However, we expect that, over time, open-source efforts will reach similar performance.
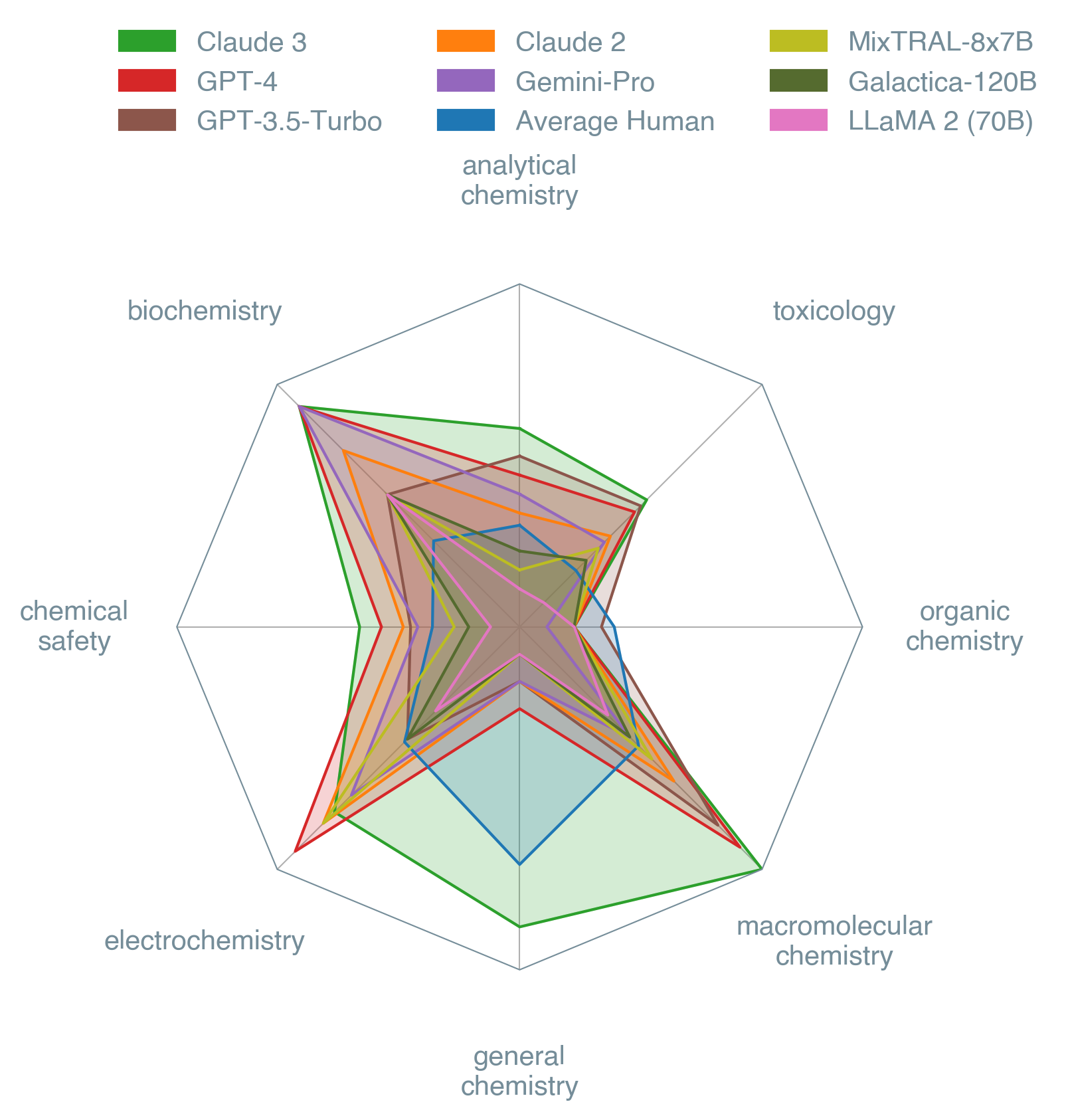
We also designed a page where one can see the current leaderboards (per topic and overall). We observed that humans are outperformed on average by the best LLM. However, there are still questions to be answered about LLMs' reasoning abilities, which would require more intricate developments to respect the criteria of a strong benchmark.
What's next for ChemBench?
We aim to have continuous releases of ChemBench and add even more diversity to the current corpus of questions. The showyourwork framework used for "ChemBench 1.0" will update the paper with new results as we gather more data on humans' and models' performance. This is the first paper of its kind in chemistry (i.e., a paper that gets updated automatically). We would be happy if the community is engaged in our future efforts and participates in the discussions section on GitHub.
Several things can be done to participate in this cool project:
- Submit your own models
- Submit your answers in the web application
- Explore our leaderboards and contact us with suggestions
- Make Pull-requests/Open issues for necessary improvements
This was our first step on the journey of better understanding what LLMs can do for chemistry and to learn how we can improve as well as best use them safely. There are many more things to come and we are excited to build with you together on the foundation we laid with the initial release of ChemBench.
Development efforts
This is our group's first joint paper! So here are some highlights!
- We broke GitHub with the amount of Pull-Requests and files changed.
- We built a completely reproducible paper
- We built a custom web application
- We surveyed many experts on topics of interest to the ML for the chemistry community.
- We build leaderboards for LLMs for chemistry in a similar style to the Open LLM Leaderboard and the matbench leaderboard
- We all learned a lot along the way!
References
Footnotes
-
Schulze Balhorn, L. et al. Empirical assessment of ChatGPT’s answering capabilities in natural science and engineering. Sci. Rep. 14. ↩
-
AI4Science, M. R. & Quantum, M. A. The Impact of Large Language Models on Scientific Discovery: a Preliminary Study using GPT-4. arXiv: 2311.07361 [cs.CL]. ↩
-
Castro Nascimento, C. M. & Pimentel, A. S. Do Large Language Models Under- stand Chemistry? A Conversation with ChatGPT. J. Chem. Inf. Model. 63, 1649– 1655. ↩
-
Northcutt, C. G., Athalye, A. & Mueller, J. Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks. arXiv: 2103.14749 [stat.ML] ↩